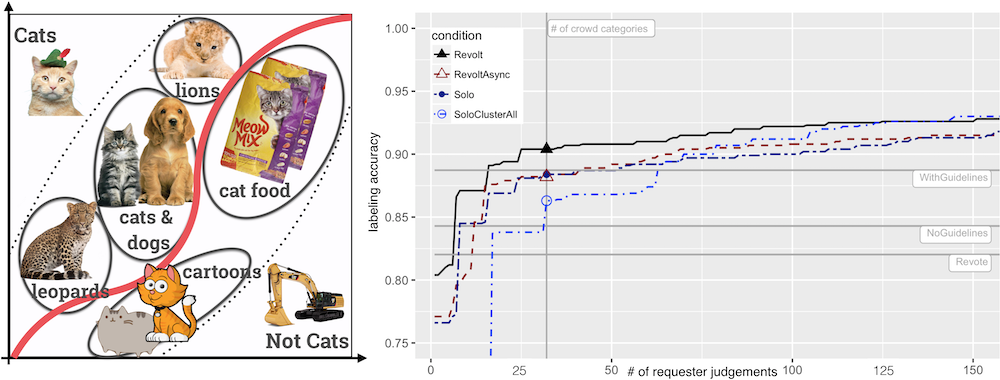
Generating comprehensive labeling guidelines for crowdworkers can be challenging for complex datasets. Revolt harnesses crowd disagreements to identify ambiguous concepts in the data and coordinates the crowd to collaboratively create rich structures for requesters to make posthoc decisions, removing the need for comprehensive guidelines and enabling dynamic label boundaries.
Work done during internship at Microsoft Research, Redmond.
Abstract
Crowdsourcing provides a scalable and efficient way to construct labeled datasets for training machine learning systems. However, creating comprehensive label guidelines for crowdworkers is often prohibitive even for seemingly simple concepts. Incomplete or ambiguous label guidelines can then result in differing interpretations of concepts and inconsistent labels. Existing approaches for improving label quality, such as worker screening or detection of poor work, are ineffective for this problem and can lead to rejection of honest work and a missed opportunity to capture rich interpretations about data. We introduce Revolt, a collaborative approach that brings ideas from expert annotation workflows to crowd-based labeling. Revolt eliminates the burden of creating detailed label guidelines by harnessing crowd disagreements to identify ambiguous concepts and create rich structures (groups of semantically related items) for post-hoc label decisions. Experiments comparing Revolt to traditional crowdsourced labeling show that Revolt produces high quality labels without requiring label guidelines in turn for an increase in monetary cost. This up front cost, however, is mitigated by Revolt’s ability to produce reusable structures that can accommodate a variety of label boundaries without requiring new data to be collected. Further comparisons of Revolt’s collaborative and non-collaborative variants show that collaboration reaches higher label accuracy with lower monetary cost.
Downloads
PDF Download ACM Digital Library Technical and Design Notes (draft)
Citation
1 2 3 4 | |
Bibtex
1 2 3 4 5 6 7 8 9 10 11 | |


